


乍一看,AI x Web3 似乎是相互独立的技术,各自基于根本不同的原理,并服务于不同的功能。然而,深入探讨会发现,这两种技术有机会平衡彼此的权衡取舍,彼此独特的优势可以相辅相成,互相提升。Balaji Srinivasan在SuperAI大会上精辟地阐述了这一互补能力的概念,激发了对这些技术如何相互作用的详细比较。
Token采用自下而上的方法,从匿名网络朋克的去中心化努力中兴起,十多年的时间通过全球众多独立实体的协同努力不断演变。相反,人工智能是通过自上而下的方法开发的,由少数科技巨头主导。这些公司决定了行业的步伐和动态,进入门槛更多是由资源密集度而非技术复杂性决定的。
这两种技术也有着截然不同的本质。本质上,Token是确定性系统,产生不可改变的结果,如哈希函数或零知识证明的可预测性。这与人工智能的概率性和通常不可预测性形成了鲜明对比。
同样,加密技术在验证方面表现出色,确保交易的真实性和安全性,并建立无信任的流程和系统,而人工智能则专注于生成,创造丰富的数字内容。然而,在创造数字丰富的过程中,确保内容来源和防止身份盗用成为一个挑战。
幸运的是,Token提供了数字丰富的对立概念——数字稀缺性。它提供了相对成熟的工具,可以推广到人工智能技术,以确保内容来源的可靠性并避免身份盗用问题。
Token的一个显著优势是其吸引大量硬件和资本进入协调网络,以服务特定目标的能力。这一能力对消耗大量计算能力的人工智能尤为有利。动员未充分利用的资源以提供更廉价的计算能力,能够显著提升人工智能的效率。
通过将这两大技术进行对比,我们不仅可以欣赏它们各自的贡献,还可以看到它们如何共同开创技术和经济的新道路。每一种技术都能弥补另一种技术的不足,创造一个更加一体化、创新的未来。在这篇博客文章中,我们旨在探索新兴的 AI x Web3产业图谱,重点介绍这些技术交叉点上一些新兴的垂直领域。
Source: IOSG Ventures
2.1 计算网络
行业图谱首先介绍了计算网络,它们试图解决受限的GPU供应问题,并尝试以不同的方式降低计算成本。值得重点关注的是以下几项:
非统一GPU互操作性:这是一个非常雄心勃勃的尝试,技术风险和不确定性都很高,但如果成功,将有可能创造出规模和影响巨大的成果,使所有计算资源变得可互换。本质上,这个想法是构建编译器和其他前提条件,使得在供应端可以插入任何硬件资源,而在需求端,所有硬件的非统一性将完全被抽象化,这样你的计算请求可以路由到网络中的任何资源。如果这一愿景成功,将降低目前对AI开发者完全主导的CUDA软件的依赖。尽管技术风险很高,许多专家对这种方法的可行性持高度怀疑态度。
高性能GPU聚合:将全球最受欢迎的GPU整合到一个分布式且无权限的网络中,而无需担心非统一GPU资源之间的互操作性问题。
商品消费级GPU聚合:指向聚合一些性能较低但可能在消费设备中可用的GPU,这些GPU是供应端最未充分利用的资源。它迎合了那些愿意牺牲性能和速度以获得更便宜、更长训练过程的人群。
2.2训练与推理
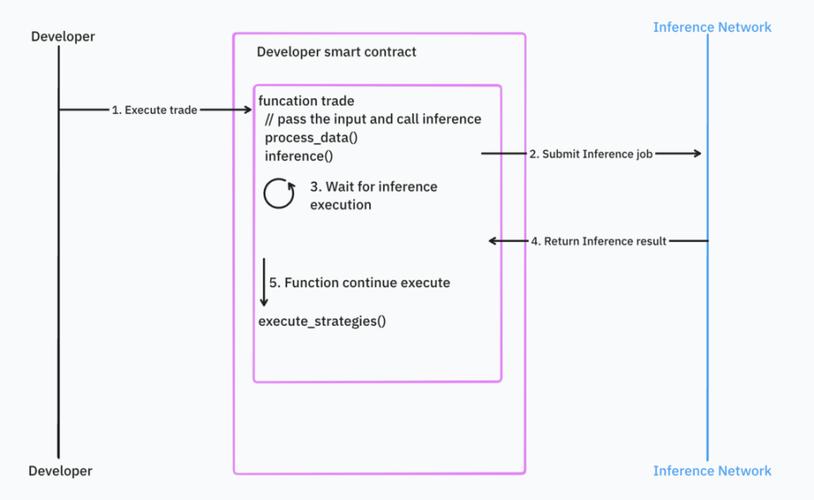
计算网络主要用于两个主要功能:训练和推理。对这些网络的需求来自于 Web 2.0 和 Web 3.0 项目。在 Web 3.0 领域,像 Bittensor 这样的项目利用计算资源进行模型微调。在推理方面,Web 3.0 项目强调过程的可验证性。这一重点催生了可验证推理作为一个市场垂直领域,项目们正在探索如何将 AI 推理集成到智能合约中,同时保持去中心化的原则。
2.3智能代理平台
接下来是智能代理平台,图谱概述了这一类别中的初创公司需要解决的核心问题:
代理互操作性和发现及通信能力:代理之间能够互相发现和通信。
代理集群构建和管理能力:代理能够组建集群并管理其他代理。
AI代理的所有权和市场:为AI代理提供所有权和市场。
这些特性强调了灵活和模块化系统的重要性,这些系统可以无缝集成到各种区块链和人工智能应用中。AI代理有可能彻底改变我们与互联网的互动方式,我们相信代理将利用基础设施来支持其操作。我们设想AI代理在以下几方面依赖基础设施:
利用分布式抓取网络访问实时网络数据
使用DeFi渠道进行代理间支付
需要经济押金不仅是为了在不当行为发生时进行惩罚,还可以提高代理的可发现性(即在发现过程中利用押金作为经济信号)
利用共识决定哪些事件应导致削减
开放的互操作性标准和代理框架以支持构建可组合的集体
根据不可变的数据历史来评估过去的表现,并实时选择合适的代理集体
Source: IOSG Ventures
2.4数据层
在AI x Web3的融合中,数据是一个核心组成部分。数据是AI竞争中的战略资产,与计算资源一道构成关键资源。然而,这一类别往往被忽视,因为业界的大部分注意力都集中在计算层面。实际上,原语在数据获取过程中提供了许多有趣的价值方向,主要包括以下两个高层次方向:
访问公共互联网数据
访问被保护的数据
访问公共互联网数据:这一方向旨在构建分布式爬虫网络,可以在几天内爬取整个互联网,获取海量数据集,或实时访问非常具体的互联网数据。然而,要爬取互联网上的大量数据集,网络需求非常高,至少需要几百个节点才能开始一些有意义的工作。幸运的是,Grass,一个分布式爬虫节点网络,已经有超过200万个节点积极向网络共享互联网带宽,目标是爬取整个互联网。这显示了经济激励在吸引宝贵资源方面的巨大潜力。
尽管Grass在公共数据方面提供了公平的竞争环境,但仍然存在利用潜在数据的难题——即专有数据集的访问问题。具体来说,仍有大量数据由于其敏感性质而以隐私保护的方式保存。许多初创公司正在利用一些密码学工具,使AI开发者能够在保持敏感信息私密的同时,利用专有数据集的基础数据结构来构建和微调大型语言模型。
联邦学习、差分隐私、可信执行环境、全同态和多方计算等技术提供了不同级别的隐私保护和权衡。Bagel的研究文章(https://blog.bagel.net/p/with-great-data-comes-great-responsibility-d67)总结了这些技术的优秀概述。这些技术不仅在机器学习过程中保护数据隐私,还可以在计算层面实现全面的隐私保护AI解决方案。
2.5数据与模型来源
数据和模型来源技术旨在建立可以向用户保证他们正在与预期模型和数据交互的过程。此外,这些技术还提供真实性和来源的保证。以水印技术为例,水印是模型来源技术之一,它将签名直接嵌入到机器学习算法中,更具体地说是直接嵌入到模型权重中,这样在检索时可以验证推理是否来自预期的模型。
2.6应用
在应用方面,设计的可能性是无限的。在上面的行业版图中,我们列出了一些随着AI技术在Web 3.0领域的应用而特别令人期待的发展案例。由于这些用例大多是自我描述的,我们在此不作额外评论。然而,值得注意的是,AI与Web 3.0的交汇有可能重塑领域的许多垂直领域,因为这些新原语为开发者创造创新用例和优化现有用例提供了更多的自由度。
总结
AI x Web3 融合带来了充满创新和潜力的前景。通过利用每种技术的独特优势,我们可以解决各种挑战,并开辟新的技术路径。在探索这个新兴行业时, AI x Web3之间的协同作用可以推动进步,重塑我们的未来数字体验和我们在网络上的互动方式。
数字稀缺与数字丰富的融合、未充分利用资源的动员以实现计算效率,以及安全、隐私保护的数据实践的建立,将定义下一代技术演进的时代。
然而,我们必须认识到,这个行业仍处于起步阶段,目前的行业版图可能在短时间内变得过时。快速的创新节奏意味着今天的前沿解决方案可能很快会被新的突破所取代。尽管如此,所探讨的基础概念——如计算网络、代理平台和数据协议——突显了人工智能与Web 3.0融汇的巨大可能性。